Data Transformation
Prerequisites (dplyr)
Here we’re going to focus on how to use the dplyr package. We’ll illustrate the key ideas using data from the nycflights13 package.
suppressWarnings(library(nycflights13))
suppressWarnings(library(tidyverse))nycflights13
To explore the basic data manipulation verbs of dplyr, we’ll use
nycflights13::flights. This data frame contains all 336,776
flights that departed from New York City in 2013. The data is documented
in ?flights.
flights## # A tibble: 336,776 × 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay
## <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl>
## 1 2013 1 1 517 515 2 830 819 11
## 2 2013 1 1 533 529 4 850 830 20
## 3 2013 1 1 542 540 2 923 850 33
## 4 2013 1 1 544 545 -1 1004 1022 -18
## 5 2013 1 1 554 600 -6 812 837 -25
## 6 2013 1 1 554 558 -4 740 728 12
## 7 2013 1 1 555 600 -5 913 854 19
## 8 2013 1 1 557 600 -3 709 723 -14
## 9 2013 1 1 557 600 -3 838 846 -8
## 10 2013 1 1 558 600 -2 753 745 8
## # … with 336,766 more rows, and 10 more variables: carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>You might notice that this data frame prints a little differently from other dataframes.
It prints differently because it’s a TIBBLE data frames.
You might also have noticed the row of three (or four) letter abbreviations under the column names. These describe the type of each variable:
intstands for integers.dblstands for doubles, or real numbers.chrstands for character vectors, or strings.dttmstands for date-times (a date + a time).
There are 3 other common types of variables that are not present in this dataset but we will encounter later in the book:
lglstands for logical, vectors that contain onlyTRUEorFALSE.fctrstands for factors, which R uses to represent categorical variables with fixed possible values.datestands for dates.
dplyr basics
Six key dplyr functions that allow you to solve the vast majority of your data manipulation challenges
| Function | Summary |
|---|---|
filter() |
Pick observations by their values |
arrange() |
Reorder the rows |
select() |
Pick variables by their names. |
mutate() |
Create new variables with functions of existing variables |
summarise() |
Collapse many values down to a single summary |
group_by() |
Changes the scope of each function from operating on the entire dataset to operating on it group-by-group |
Filter rows with filter()
filter() allows you to subset observations based on
their values. The first argument is the name of the data frame.
The second and subsequent arguments are the expressions that filter the data frame.
For example, we can select all flights on January 1st with:
jan1 <- filter(flights, month == 1, day == 1)
jan1## # A tibble: 842 × 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay
## <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl>
## 1 2013 1 1 517 515 2 830 819 11
## 2 2013 1 1 533 529 4 850 830 20
## 3 2013 1 1 542 540 2 923 850 33
## 4 2013 1 1 544 545 -1 1004 1022 -18
## 5 2013 1 1 554 600 -6 812 837 -25
## 6 2013 1 1 554 558 -4 740 728 12
## 7 2013 1 1 555 600 -5 913 854 19
## 8 2013 1 1 557 600 -3 709 723 -14
## 9 2013 1 1 557 600 -3 838 846 -8
## 10 2013 1 1 558 600 -2 753 745 8
## # … with 832 more rows, and 10 more variables: carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dttm>Arrange rows with arrange()
arrange() works similarly to filter()
except that instead of selecting rows, it changes their
order.
It takes a data frame and a set of column names (or more complicated expressions) to order by.
If you provide more than one column name, each additional column will be used to break ties in the values of preceding columns:
arrange(flights, year, month, day)## # A tibble: 336,776 × 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay
## <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl>
## 1 2013 1 1 517 515 2 830 819 11
## 2 2013 1 1 533 529 4 850 830 20
## 3 2013 1 1 542 540 2 923 850 33
## 4 2013 1 1 544 545 -1 1004 1022 -18
## 5 2013 1 1 554 600 -6 812 837 -25
## 6 2013 1 1 554 558 -4 740 728 12
## 7 2013 1 1 555 600 -5 913 854 19
## 8 2013 1 1 557 600 -3 709 723 -14
## 9 2013 1 1 557 600 -3 838 846 -8
## 10 2013 1 1 558 600 -2 753 745 8
## # … with 336,766 more rows, and 10 more variables: carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>Use desc() to re-order by a column in
descending order:
arrange(flights, desc(arr_delay))## # A tibble: 336,776 × 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay
## <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl>
## 1 2013 1 9 641 900 1301 1242 1530 1272
## 2 2013 6 15 1432 1935 1137 1607 2120 1127
## 3 2013 1 10 1121 1635 1126 1239 1810 1109
## 4 2013 9 20 1139 1845 1014 1457 2210 1007
## 5 2013 7 22 845 1600 1005 1044 1815 989
## 6 2013 4 10 1100 1900 960 1342 2211 931
## 7 2013 3 17 2321 810 911 135 1020 915
## 8 2013 7 22 2257 759 898 121 1026 895
## 9 2013 12 5 756 1700 896 1058 2020 878
## 10 2013 5 3 1133 2055 878 1250 2215 875
## # … with 336,766 more rows, and 10 more variables: carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>
Missing values are always sorted at the end
df <- tibble(x = c(5, 2, NA))
arrange(df, x)## # A tibble: 3 × 1
## x
## <dbl>
## 1 2
## 2 5
## 3 NAarrange(df, desc(x))## # A tibble: 3 × 1
## x
## <dbl>
## 1 5
## 2 2
## 3 NASelect columns with select()
The first challenge is often narrowing in on the variables you’re actually interested in.
select() allows you to rapidly zoom in on a useful
subset using operations based on the names of the variables.
# Select columns by name
select(flights, year, month, day)## # A tibble: 336,776 × 3
## year month day
## <int> <int> <int>
## 1 2013 1 1
## 2 2013 1 1
## 3 2013 1 1
## 4 2013 1 1
## 5 2013 1 1
## 6 2013 1 1
## 7 2013 1 1
## 8 2013 1 1
## 9 2013 1 1
## 10 2013 1 1
## # … with 336,766 more rows# Select all columns between year and day (INCLUSIVE)
select(flights, year:day)## # A tibble: 336,776 × 3
## year month day
## <int> <int> <int>
## 1 2013 1 1
## 2 2013 1 1
## 3 2013 1 1
## 4 2013 1 1
## 5 2013 1 1
## 6 2013 1 1
## 7 2013 1 1
## 8 2013 1 1
## 9 2013 1 1
## 10 2013 1 1
## # … with 336,766 more rows# Select all columns except those from year to day (INCLUSIVE)
select(flights, -(year:day))## # A tibble: 336,776 × 16
## dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay carrier flight
## <int> <int> <dbl> <int> <int> <dbl> <chr> <int>
## 1 517 515 2 830 819 11 UA 1545
## 2 533 529 4 850 830 20 UA 1714
## 3 542 540 2 923 850 33 AA 1141
## 4 544 545 -1 1004 1022 -18 B6 725
## 5 554 600 -6 812 837 -25 DL 461
## 6 554 558 -4 740 728 12 UA 1696
## 7 555 600 -5 913 854 19 B6 507
## 8 557 600 -3 709 723 -14 EV 5708
## 9 557 600 -3 838 846 -8 B6 79
## 10 558 600 -2 753 745 8 AA 301
## # … with 336,766 more rows, and 8 more variables: tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
There are helper functions you can use within
select():
| Function | Summary |
|---|---|
starts_with |
matches names that begin with “abc” |
ends_with |
matches names that end with “xyz” |
contains |
matches names that contain “ijk” |
matches |
matches a pattern |
num_range |
Matches a numerical range like x1,
x2 and x3 |
rename |
rename variables |
select(flights, matches("^dep"))## # A tibble: 336,776 × 2
## dep_time dep_delay
## <int> <dbl>
## 1 517 2
## 2 533 4
## 3 542 2
## 4 544 -1
## 5 554 -6
## 6 554 -4
## 7 555 -5
## 8 557 -3
## 9 557 -3
## 10 558 -2
## # … with 336,766 more rowsrename(flights, tail_num = tailnum)## # A tibble: 336,776 × 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay
## <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl>
## 1 2013 1 1 517 515 2 830 819 11
## 2 2013 1 1 533 529 4 850 830 20
## 3 2013 1 1 542 540 2 923 850 33
## 4 2013 1 1 544 545 -1 1004 1022 -18
## 5 2013 1 1 554 600 -6 812 837 -25
## 6 2013 1 1 554 558 -4 740 728 12
## 7 2013 1 1 555 600 -5 913 854 19
## 8 2013 1 1 557 600 -3 709 723 -14
## 9 2013 1 1 557 600 -3 838 846 -8
## 10 2013 1 1 558 600 -2 753 745 8
## # … with 336,766 more rows, and 10 more variables: carrier <chr>, flight <int>,
## # tail_num <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>Add new variables with mutate()
mutate() always adds new columns at the end of your
dataset.
flights_sml <- select(flights,
year:day,
ends_with("delay"),
distance,
air_time
)
mutate(flights_sml,
gain = arr_delay - dep_delay,
speed = distance / air_time * 60
)## # A tibble: 336,776 × 9
## year month day dep_delay arr_delay distance air_time gain speed
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 2 11 1400 227 9 370.
## 2 2013 1 1 4 20 1416 227 16 374.
## 3 2013 1 1 2 33 1089 160 31 408.
## 4 2013 1 1 -1 -18 1576 183 -17 517.
## 5 2013 1 1 -6 -25 762 116 -19 394.
## 6 2013 1 1 -4 12 719 150 16 288.
## 7 2013 1 1 -5 19 1065 158 24 404.
## 8 2013 1 1 -3 -14 229 53 -11 259.
## 9 2013 1 1 -3 -8 944 140 -5 405.
## 10 2013 1 1 -2 8 733 138 10 319.
## # … with 336,766 more rowsNote that you can refer to columns that you have just created:
mutate(flights_sml,
gain = arr_delay - dep_delay,
hours = air_time / 60,
gain_per_hour = gain / hours # <-- Here
)## # A tibble: 336,776 × 10
## year month day dep_delay arr_delay distance air_time gain hours gain_per_hour
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 2 11 1400 227 9 3.78 2.38
## 2 2013 1 1 4 20 1416 227 16 3.78 4.23
## 3 2013 1 1 2 33 1089 160 31 2.67 11.6
## 4 2013 1 1 -1 -18 1576 183 -17 3.05 -5.57
## 5 2013 1 1 -6 -25 762 116 -19 1.93 -9.83
## 6 2013 1 1 -4 12 719 150 16 2.5 6.4
## 7 2013 1 1 -5 19 1065 158 24 2.63 9.11
## 8 2013 1 1 -3 -14 229 53 -11 0.883 -12.5
## 9 2013 1 1 -3 -8 944 140 -5 2.33 -2.14
## 10 2013 1 1 -2 8 733 138 10 2.3 4.35
## # … with 336,766 more rows
If you only want to keep the new variables, use
transmute():
transmute(flights,
gain = arr_delay - dep_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)## # A tibble: 336,776 × 3
## gain hours gain_per_hour
## <dbl> <dbl> <dbl>
## 1 9 3.78 2.38
## 2 16 3.78 4.23
## 3 31 2.67 11.6
## 4 -17 3.05 -5.57
## 5 -19 1.93 -9.83
## 6 16 2.5 6.4
## 7 24 2.63 9.11
## 8 -11 0.883 -12.5
## 9 -5 2.33 -2.14
## 10 10 2.3 4.35
## # … with 336,766 more rowsUseful creation functions
There are many functions for creating new variables that you can use
with mutate().
The key property is that the function must be VECTORIZED. In other words, It must take a vector of values as input and return a vector with the same number of values as output.
Here is a selection of functions that are frequently useful:
Arithmetic operators:
+,-,*,/,^.These are all vectorised, using the so called “recycling rules”. If one parameter is shorter than the other, it will be automatically extended to be the same length. This is most useful when one of the arguments is a single number:
air_time / 60,hours * 60 + minute, etc.Arithmetic operators are also useful in conjunction with the aggregate functions you’ll learn about later. For example,
x / sum(x)calculates the proportion of a total, andy - mean(y)computes the difference from the mean.
Modular arithmetic:
%/%(integer division) and%%(remainder).Modular arithmetic is a handy tool because it allows you to break integers up into pieces. For example, in the flights dataset, you can compute
hourandminutefromdep_timewith:transmute(flights, dep_time, hour = dep_time %/% 100, minute = dep_time %% 100 )## # A tibble: 336,776 × 3 ## dep_time hour minute ## <int> <dbl> <dbl> ## 1 517 5 17 ## 2 533 5 33 ## 3 542 5 42 ## 4 544 5 44 ## 5 554 5 54 ## 6 554 5 54 ## 7 555 5 55 ## 8 557 5 57 ## 9 557 5 57 ## 10 558 5 58 ## # … with 336,766 more rows
Logs:
log(),log2(),log10().Logarithms are an useful transformation for dealing with data that ranges across multiple orders of magnitude. They also convert multiplicative relationships to additive.
All else being equal, I recommend using
log2()because it’s easy to interpret: a difference of 1 on the log scale corresponds to doubling on the original scale and a difference of -1 corresponds to halving.
Offsets:
lead()andlag()allow you to refer to leading (“next”) or lagging (“previous”) values.This allows you to compute running differences (e.g.
x - lag(x)) or find when values change (x != lag(x)). They are most useful in conjunction withgroup_by(), which you’ll learn about shortly.x <- 1:10 #lagging ("previous") lag(x)## [1] NA 1 2 3 4 5 6 7 8 9#leading ("next") lead(x)## [1] 2 3 4 5 6 7 8 9 10 NA# running differences x - lag(x)## [1] NA 1 1 1 1 1 1 1 1 1# changing values x != lag(x)## [1] NA TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
Cumulative and rolling aggregates:
cumsum(),cumprod(),cummin(),cummax()R provides functions for running sums, products, mins and maxes:
cumsum(),cumprod(),cummin(),cummax(); and dplyr providescummean()for cumulative means. If you need rolling aggregates (i.e. a sum computed over a rolling window), try the RcppRoll package.x## [1] 1 2 3 4 5 6 7 8 9 10cumsum(x)## [1] 1 3 6 10 15 21 28 36 45 55cummean(x)## [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5
- Logical comparisons,
<,<=,>,>=,!=, which you learned about earlier.
Ranking:
min_rank(),row_number(),dense_rank(),percent_rank(),cume_dist().there are a number of ranking functions, but you should start with
min_rank(). It does the most usual type of ranking (e.g. 1st, 2nd, 2nd, 4th). The default gives smallest values the small ranks; usedesc(x)to give the largest values the smallest ranks.y <- c(1, 2, 2, 3, 4) min_rank(y)## [1] 1 2 2 4 5min_rank(desc(y))## [1] 5 3 3 2 1If
min_rank()doesn’t do what you need, look at the variantsrow_number(),dense_rank(),percent_rank(),cume_dist(),ntile(). See their help pages for more details.row_number(y)## [1] 1 2 3 4 5# like min_rank(), but with no gaps between rank dense_rank(y)## [1] 1 2 2 3 4#a number between 0 and 1 computed by rescaling min_rank to [0, 1] percent_rank(y)## [1] 0.00 0.25 0.25 0.75 1.00#a cumulative distribution function. Proportion of all values less than or equal to the current rank. cume_dist(y)## [1] 0.2 0.6 0.6 0.8 1.0
Grouped summaries with summarise()
summarise() collapses a data frame to a single row:
summarise(flights, delay = mean(dep_delay, na.rm = TRUE))## # A tibble: 1 × 1
## delay
## <dbl>
## 1 12.6summarise() is not useful unless we pair it with
group_by().
This changes the unit of analysis from the complete dataset to individual groups.
Then, when you use the dplyr verbs on a grouped data frame they’ll be automatically applied “by group”.
For example, if we applied exactly the same code to a data frame grouped by date, we get the average delay per date:
by_day <- group_by(flights, year, month, day)
summarise(by_day, delay = mean(dep_delay, na.rm = TRUE))## `summarise()` has grouped output by 'year', 'month'. You can override using the `.groups`
## argument.## # A tibble: 365 × 4
## # Groups: year, month [12]
## year month day delay
## <int> <int> <int> <dbl>
## 1 2013 1 1 11.5
## 2 2013 1 2 13.9
## 3 2013 1 3 11.0
## 4 2013 1 4 8.95
## 5 2013 1 5 5.73
## 6 2013 1 6 7.15
## 7 2013 1 7 5.42
## 8 2013 1 8 2.55
## 9 2013 1 9 2.28
## 10 2013 1 10 2.84
## # … with 355 more rowsTogether group_by() and summarise() provide
one of the tools that you’ll use most commonly when working with dplyr:
grouped summaries. But before we go any further with this, we need to
introduce a powerful new idea: the pipe.
Combining multiple operations with the pipe %>%
Suppose you have this code:
by_dest <- group_by(flights, dest)
delay <- summarise(by_dest,
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
)
delay <- filter(delay, count > 20, dest != "HNL")
ggplot(data = delay, mapping = aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE) +xlab("Distance")+ylab("Delay")## `geom_smooth()` using method = 'loess' and formula 'y ~ x'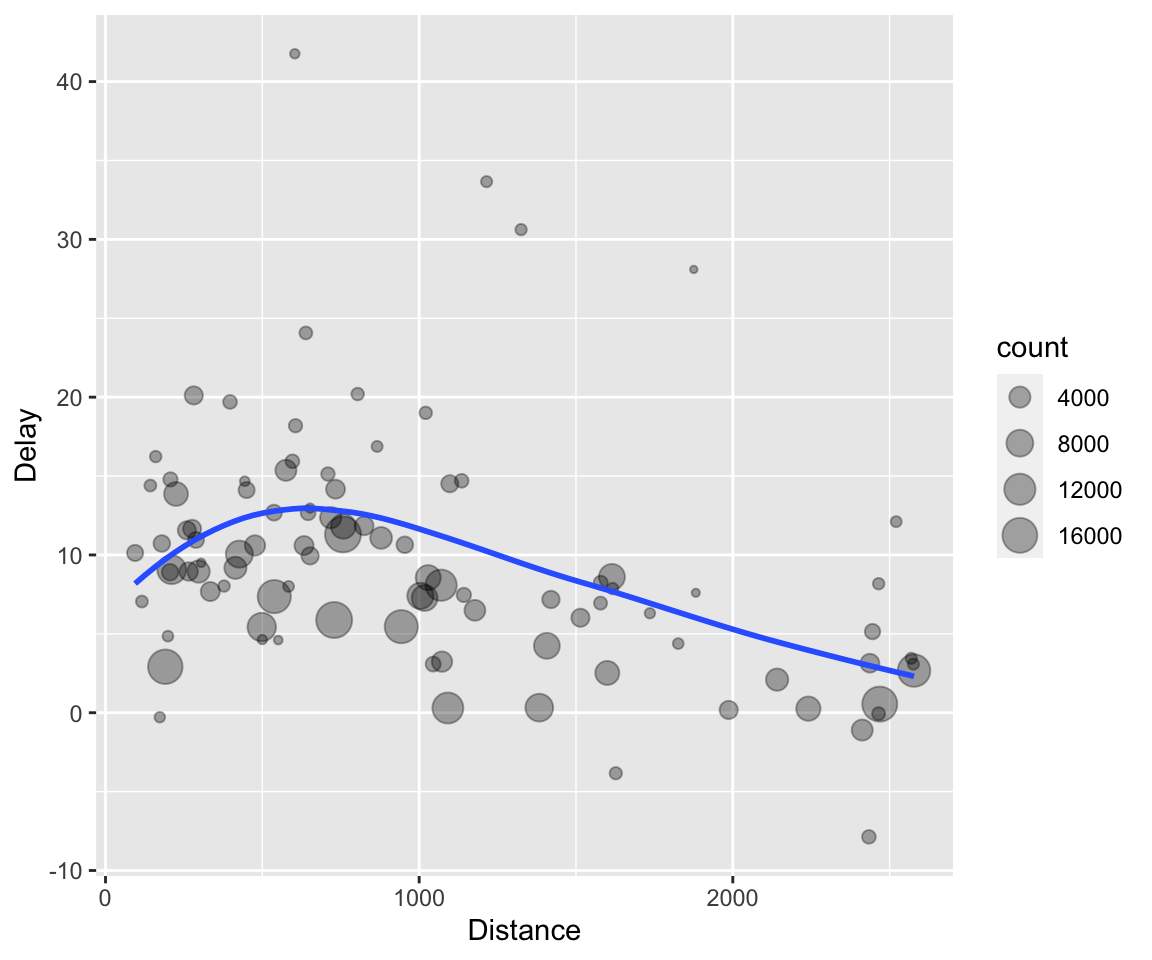
There is another way to tackle the same problem with the pipe
%>%:
delays <- flights %>%
group_by(dest) %>%
summarise(
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
) %>%
filter(count > 20, dest != "HNL")
ggplot(data = delays, mapping = aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3, col='red') +
geom_smooth(se = FALSE)+xlab("Distance")+ylab("Delay")## `geom_smooth()` using method = 'loess' and formula 'y ~ x'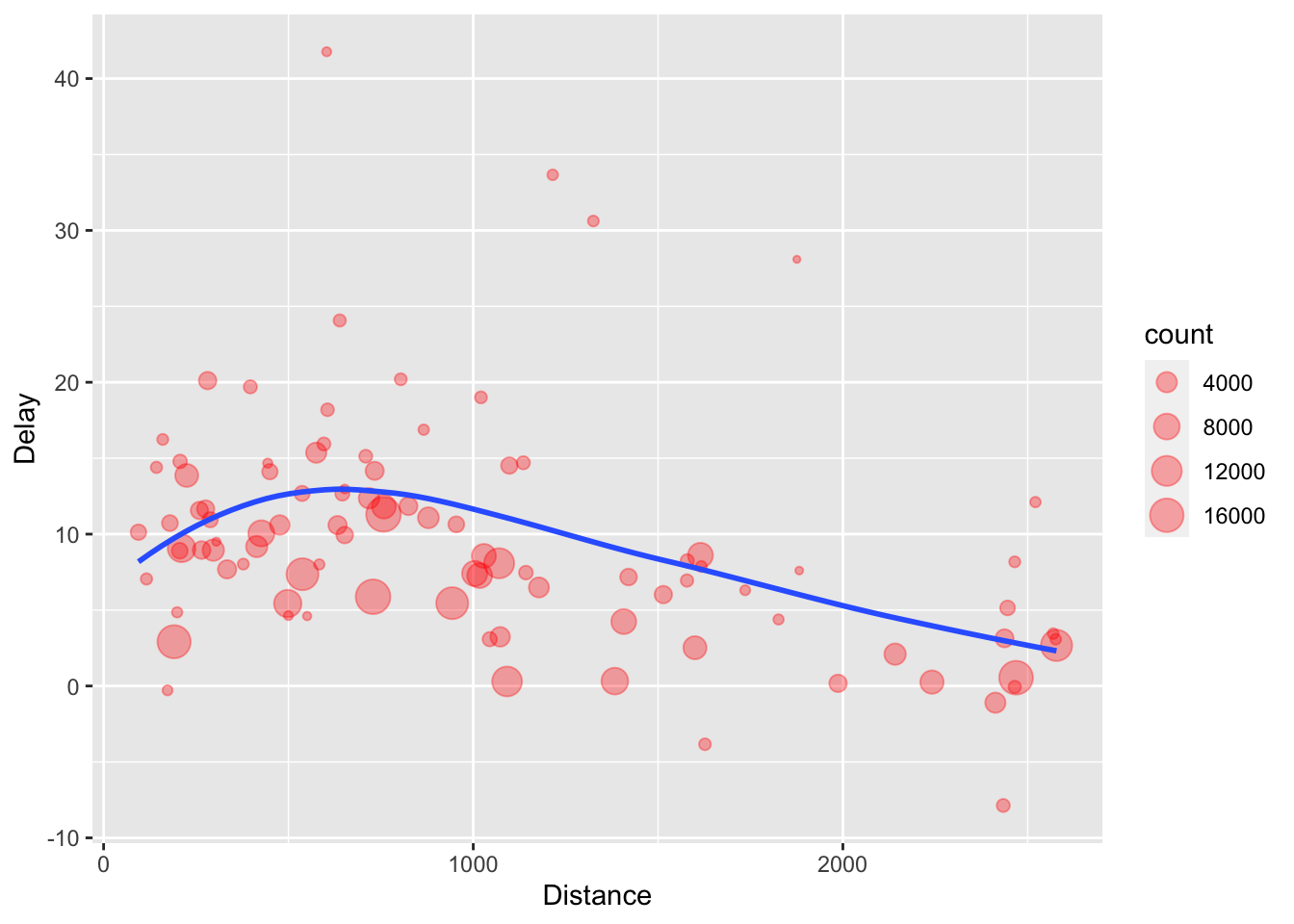
Missing values na.rm
All aggregation functions have an na.rm argument which
removes the missing values prior to computation:
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay, na.rm = TRUE))## `summarise()` has grouped output by 'year', 'month'. You can override using the `.groups`
## argument.## # A tibble: 365 × 4
## # Groups: year, month [12]
## year month day mean
## <int> <int> <int> <dbl>
## 1 2013 1 1 11.5
## 2 2013 1 2 13.9
## 3 2013 1 3 11.0
## 4 2013 1 4 8.95
## 5 2013 1 5 5.73
## 6 2013 1 6 7.15
## 7 2013 1 7 5.42
## 8 2013 1 8 2.55
## 9 2013 1 9 2.28
## 10 2013 1 10 2.84
## # … with 355 more rowsIn this case, we could tackle the problem by first removing the cancelled flights.
not_cancelled <- flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
not_cancelled %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))## `summarise()` has grouped output by 'year', 'month'. You can override using the `.groups`
## argument.## # A tibble: 365 × 4
## # Groups: year, month [12]
## year month day mean
## <int> <int> <int> <dbl>
## 1 2013 1 1 11.4
## 2 2013 1 2 13.7
## 3 2013 1 3 10.9
## 4 2013 1 4 8.97
## 5 2013 1 5 5.73
## 6 2013 1 6 7.15
## 7 2013 1 7 5.42
## 8 2013 1 8 2.56
## 9 2013 1 9 2.30
## 10 2013 1 10 2.84
## # … with 355 more rowsCounts n()
It’s always a good idea to include either a count (n()),
or a count of non-missing values (sum(!is.na(x))).
delays <- not_cancelled %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay, na.rm = TRUE),
n = n()
)
ggplot(data = delays, mapping = aes(x = n, y = delay)) +
geom_point(alpha = 1/10)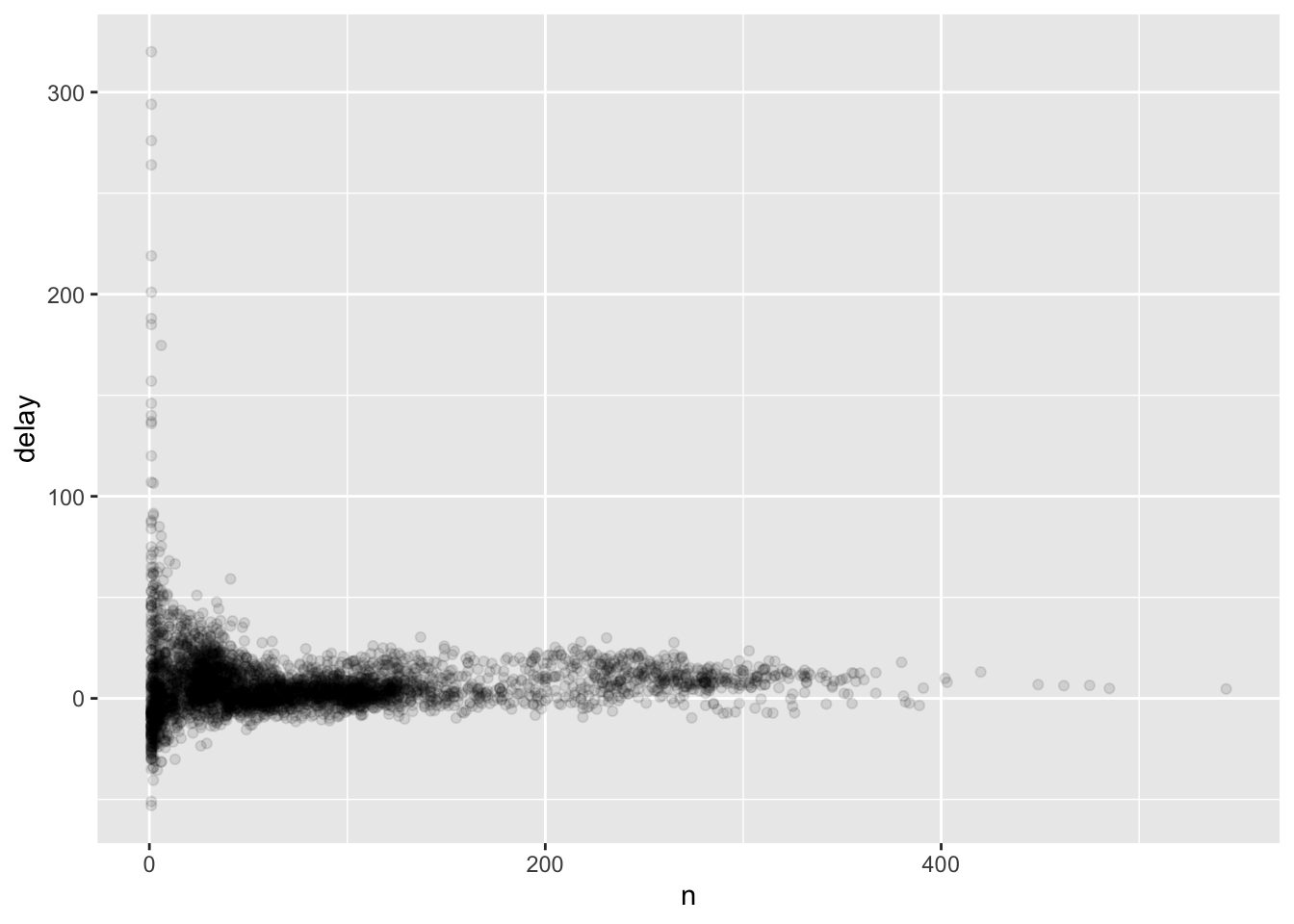
Useful summary functions
Just using means, counts, and sum can get you a long way, but R provides many other useful summary functions:
Measures of location:
mean(x)andmedian(x).The mean is the sum divided by the length; the median is a value where 50% of
xis above it, and 50% is below it.It can be useful to combine aggregation with logical subsetting.
not_cancelled %>% group_by(year, month, day) %>% summarise( avg_delay1 = mean(arr_delay), avg_delay2 = mean(arr_delay[arr_delay > 0]) # the average positive delay )## `summarise()` has grouped output by 'year', 'month'. You can override using the `.groups` ## argument.## # A tibble: 365 × 5 ## # Groups: year, month [12] ## year month day avg_delay1 avg_delay2 ## <int> <int> <int> <dbl> <dbl> ## 1 2013 1 1 12.7 32.5 ## 2 2013 1 2 12.7 32.0 ## 3 2013 1 3 5.73 27.7 ## 4 2013 1 4 -1.93 28.3 ## 5 2013 1 5 -1.53 22.6 ## 6 2013 1 6 4.24 24.4 ## 7 2013 1 7 -4.95 27.8 ## 8 2013 1 8 -3.23 20.8 ## 9 2013 1 9 -0.264 25.6 ## 10 2013 1 10 -5.90 27.3 ## # … with 355 more rows
Measures of spread:
sd(x),IQR(x),mad(x).Function Meaning Definition sd()Standard deviation IQR()Interquartile range difference between the 75th and 25th percentiles of the data. mad()Median Abosolute deviation the median of the absolute deviations from the data median The mean squared deviation, or standard deviation or sd for short, is the standard measure of spread. The interquartile range
IQR()and median absolute deviationmad(x)are robust equivalents that may be more useful if you have outliers.# Why is distance to some destinations more variable than to others? not_cancelled %>% group_by(dest) %>% summarise(distance_sd = sd(distance), distance_mad = mad(distance) ) %>% arrange(desc(distance_sd))## # A tibble: 104 × 3 ## dest distance_sd distance_mad ## <chr> <dbl> <dbl> ## 1 EGE 10.5 1.48 ## 2 SAN 10.4 0 ## 3 SFO 10.2 0 ## 4 HNL 10.0 0 ## 5 SEA 9.98 0 ## 6 LAS 9.91 0 ## 7 PDX 9.87 0 ## 8 PHX 9.86 0 ## 9 LAX 9.66 0 ## 10 IND 9.46 0 ## # … with 94 more rows
Measures of rank:
min(x),quantile(x, 0.25),max(x).Quantiles are a generalisation of the median. For example,
quantile(x, 0.25)will find a value ofxthat is greater than 25% of the values, and less than the remaining 75%.# When do the first and last flights leave each day? not_cancelled %>% group_by(year, month, day) %>% summarise( first = min(dep_time), last = max(dep_time) )## `summarise()` has grouped output by 'year', 'month'. You can override using the `.groups` ## argument.## # A tibble: 365 × 5 ## # Groups: year, month [12] ## year month day first last ## <int> <int> <int> <int> <int> ## 1 2013 1 1 517 2356 ## 2 2013 1 2 42 2354 ## 3 2013 1 3 32 2349 ## 4 2013 1 4 25 2358 ## 5 2013 1 5 14 2357 ## 6 2013 1 6 16 2355 ## 7 2013 1 7 49 2359 ## 8 2013 1 8 454 2351 ## 9 2013 1 9 2 2252 ## 10 2013 1 10 3 2320 ## # … with 355 more rows
Measures of position:
first(x),nth(x, 2),last(x).These work similarly to
x[1],x[2], andx[length(x)]but let you set a default value if that position does not exist (i.e. you’re trying to get the 3rd element from a group that only has two elements). For example, we can find the first and last departure for each day:not_cancelled %>% group_by(year, month, day) %>% summarise( first_dep = first(dep_time), last_dep = last(dep_time) )## `summarise()` has grouped output by 'year', 'month'. You can override using the `.groups` ## argument.## # A tibble: 365 × 5 ## # Groups: year, month [12] ## year month day first_dep last_dep ## <int> <int> <int> <int> <int> ## 1 2013 1 1 517 2356 ## 2 2013 1 2 42 2354 ## 3 2013 1 3 32 2349 ## 4 2013 1 4 25 2358 ## 5 2013 1 5 14 2357 ## 6 2013 1 6 16 2355 ## 7 2013 1 7 49 2359 ## 8 2013 1 8 454 2351 ## 9 2013 1 9 2 2252 ## 10 2013 1 10 3 2320 ## # … with 355 more rowsThese functions are complementary to filtering on ranks. Filtering gives you all variables, with each observation in a separate row:
not_cancelled %>% group_by(year, month, day) %>% mutate(r = min_rank(desc(dep_time))) %>% filter(r %in% range(r))## # A tibble: 770 × 20 ## # Groups: year, month, day [365] ## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay ## <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> ## 1 2013 1 1 517 515 2 830 819 11 ## 2 2013 1 1 2356 2359 -3 425 437 -12 ## 3 2013 1 2 42 2359 43 518 442 36 ## 4 2013 1 2 2354 2359 -5 413 437 -24 ## 5 2013 1 3 32 2359 33 504 442 22 ## 6 2013 1 3 2349 2359 -10 434 445 -11 ## 7 2013 1 4 25 2359 26 505 442 23 ## 8 2013 1 4 2358 2359 -1 429 437 -8 ## 9 2013 1 4 2358 2359 -1 436 445 -9 ## 10 2013 1 5 14 2359 15 503 445 18 ## # … with 760 more rows, and 11 more variables: carrier <chr>, flight <int>, tailnum <chr>, ## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, ## # time_hour <dttm>, r <int>
Counts:
n()n()takes no arguments and returns the size of the current group. To count the number of non-missing values, usesum(!is.na(x)). To count the number of distinct (unique) values, usen_distinct(x).# Which destinations have the most carriers? not_cancelled %>% group_by(dest) %>% summarise(carriers = n_distinct(carrier)) %>% arrange(desc(carriers))## # A tibble: 104 × 2 ## dest carriers ## <chr> <int> ## 1 ATL 7 ## 2 BOS 7 ## 3 CLT 7 ## 4 ORD 7 ## 5 TPA 7 ## 6 AUS 6 ## 7 DCA 6 ## 8 DTW 6 ## 9 IAD 6 ## 10 MSP 6 ## # … with 94 more rowsCounts are so useful that dplyr provides a simple helper if all you want is a count:
not_cancelled %>% count(dest)## # A tibble: 104 × 2 ## dest n ## <chr> <int> ## 1 ABQ 254 ## 2 ACK 264 ## 3 ALB 418 ## 4 ANC 8 ## 5 ATL 16837 ## 6 AUS 2411 ## 7 AVL 261 ## 8 BDL 412 ## 9 BGR 358 ## 10 BHM 269 ## # … with 94 more rowsYou can optionally provide a weight variable. For example, you could use this to “count” (sum) the total number of miles a plane flew:
not_cancelled %>% count(tailnum, wt = distance)## # A tibble: 4,037 × 2 ## tailnum n ## <chr> <dbl> ## 1 D942DN 3418 ## 2 N0EGMQ 239143 ## 3 N10156 109664 ## 4 N102UW 25722 ## 5 N103US 24619 ## 6 N104UW 24616 ## 7 N10575 139903 ## 8 N105UW 23618 ## 9 N107US 21677 ## 10 N108UW 32070 ## # … with 4,027 more rows
Counts and proportions of logical values:
sum(x > 10),mean(y == 0).When used with numeric functions,
TRUEis converted to 1 andFALSEto 0. This makessum()andmean()very useful:sum(x)gives the number ofTRUEs inx, andmean(x)gives the proportion.# How many flights left before 5am? (these usually indicate delayed # flights from the previous day) not_cancelled %>% group_by(year, month, day) %>% summarise(n_early = sum(dep_time < 500))## `summarise()` has grouped output by 'year', 'month'. You can override using the `.groups` ## argument.## # A tibble: 365 × 4 ## # Groups: year, month [12] ## year month day n_early ## <int> <int> <int> <int> ## 1 2013 1 1 0 ## 2 2013 1 2 3 ## 3 2013 1 3 4 ## 4 2013 1 4 3 ## 5 2013 1 5 3 ## 6 2013 1 6 2 ## 7 2013 1 7 2 ## 8 2013 1 8 1 ## 9 2013 1 9 3 ## 10 2013 1 10 3 ## # … with 355 more rows# What proportion of flights are delayed by more than an hour? not_cancelled %>% group_by(year, month, day) %>% summarise(hour_perc = mean(arr_delay > 60))## `summarise()` has grouped output by 'year', 'month'. You can override using the `.groups` ## argument.## # A tibble: 365 × 4 ## # Groups: year, month [12] ## year month day hour_perc ## <int> <int> <int> <dbl> ## 1 2013 1 1 0.0722 ## 2 2013 1 2 0.0851 ## 3 2013 1 3 0.0567 ## 4 2013 1 4 0.0396 ## 5 2013 1 5 0.0349 ## 6 2013 1 6 0.0470 ## 7 2013 1 7 0.0333 ## 8 2013 1 8 0.0213 ## 9 2013 1 9 0.0202 ## 10 2013 1 10 0.0183 ## # … with 355 more rows
Grouping and ungrupping by multiple variables
When you group by multiple variables, each summary peels off one level of the grouping. That makes it easy to progressively roll up a dataset:
daily <- group_by(flights, year, month, day)
(per_day <- summarise(daily, flights = n()))## `summarise()` has grouped output by 'year', 'month'. You can override using the `.groups`
## argument.## # A tibble: 365 × 4
## # Groups: year, month [12]
## year month day flights
## <int> <int> <int> <int>
## 1 2013 1 1 842
## 2 2013 1 2 943
## 3 2013 1 3 914
## 4 2013 1 4 915
## 5 2013 1 5 720
## 6 2013 1 6 832
## 7 2013 1 7 933
## 8 2013 1 8 899
## 9 2013 1 9 902
## 10 2013 1 10 932
## # … with 355 more rowsIf you need to remove grouping, and return to operations on ungrouped
data, use ungroup().
daily %>%
ungroup() %>% # no longer grouped by date
summarise(flights = n()) # all flights## # A tibble: 1 × 1
## flights
## <int>
## 1 336776Grouped mutates (and filters)
Grouping is most useful in conjunction with summarise(),
but you can also do convenient operations with mutate() and
filter():
Find the worst members of each group:
flights_sml %>% group_by(year, month, day) %>% filter(rank(desc(arr_delay)) < 10)## # A tibble: 3,306 × 7 ## # Groups: year, month, day [365] ## year month day dep_delay arr_delay distance air_time ## <int> <int> <int> <dbl> <dbl> <dbl> <dbl> ## 1 2013 1 1 853 851 184 41 ## 2 2013 1 1 290 338 1134 213 ## 3 2013 1 1 260 263 266 46 ## 4 2013 1 1 157 174 213 60 ## 5 2013 1 1 216 222 708 121 ## 6 2013 1 1 255 250 589 115 ## 7 2013 1 1 285 246 1085 146 ## 8 2013 1 1 192 191 199 44 ## 9 2013 1 1 379 456 1092 222 ## 10 2013 1 2 224 207 550 94 ## # … with 3,296 more rowsFind all groups bigger than a threshold:
popular_dests <- flights %>% group_by(dest) %>% filter(n() > 365) popular_dests## # A tibble: 332,577 × 19 ## # Groups: dest [77] ## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay ## <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> ## 1 2013 1 1 517 515 2 830 819 11 ## 2 2013 1 1 533 529 4 850 830 20 ## 3 2013 1 1 542 540 2 923 850 33 ## 4 2013 1 1 544 545 -1 1004 1022 -18 ## 5 2013 1 1 554 600 -6 812 837 -25 ## 6 2013 1 1 554 558 -4 740 728 12 ## 7 2013 1 1 555 600 -5 913 854 19 ## 8 2013 1 1 557 600 -3 709 723 -14 ## 9 2013 1 1 557 600 -3 838 846 -8 ## 10 2013 1 1 558 600 -2 753 745 8 ## # … with 332,567 more rows, and 10 more variables: carrier <chr>, flight <int>, ## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, ## # minute <dbl>, time_hour <dttm>Standardise to compute per group metrics:
popular_dests %>% filter(arr_delay > 0) %>% mutate(prop_delay = arr_delay / sum(arr_delay)) %>% select(year:day, dest, arr_delay, prop_delay)## # A tibble: 131,106 × 6 ## # Groups: dest [77] ## year month day dest arr_delay prop_delay ## <int> <int> <int> <chr> <dbl> <dbl> ## 1 2013 1 1 IAH 11 0.000111 ## 2 2013 1 1 IAH 20 0.000201 ## 3 2013 1 1 MIA 33 0.000235 ## 4 2013 1 1 ORD 12 0.0000424 ## 5 2013 1 1 FLL 19 0.0000938 ## 6 2013 1 1 ORD 8 0.0000283 ## 7 2013 1 1 LAX 7 0.0000344 ## 8 2013 1 1 DFW 31 0.000282 ## 9 2013 1 1 ATL 12 0.0000400 ## 10 2013 1 1 DTW 16 0.000116 ## # … with 131,096 more rows
A work by Matteo Cereda and Fabio Iannelli